使用NVIDIA Cosmos扩展合成数据和物理AI推理的最佳方法

人形机器人和智能汽车等新一代 AI 机器人依赖于高保真、物理感知的训练数据。如果没有多样化且具有代表性的数据集,这些系统将无法获得适当的训练,并且由于泛化性差、对现实世界变化的影响有限以及边缘案例中的行为不可预测,因此会面临测试风险。而收集大量真实数据集进行训练成本高昂、耗时费力,而且往往受限于各种可能性。
NVIDIA Cosmos 通过加速世界基础模型 (WFM) 开发来应对这一挑战。Cosmos WFM 是其平台的核心,可加快合成数据的生成,并作为后训练的基础,以开发下游领域或特定任务的物理 AI 模型来解决这些挑战。本文将探讨最新的 Cosmos WFM、其推进物理 AI 的关键功能,以及如何使用它们。
Cosmos Transfer 用于基于物理学的逼真视频
Cosmos Transfer WFM 根据结构化输入生成高保真世界场景,确保精确的空间对齐和场景构成。
通过采用 ControlNet 架构,Cosmos Transfer 可保留预训练知识,从而实现结构化、一致的输出。它利用时空控制图来动态对齐合成和真实世界的表示,从而实现对场景构图、物体放置和运动动态的精细控制。
输入:
输出:具有受控布局、物体放置和运动的逼真视频序列。

图 1. 左侧是在 NVIDIA Omniverse 中创建的虚拟仿真或“真值”。右侧是使用 Cosmos Transfer 实现的逼真转换
主要功能:
使用 Cosmos Transfer 获取可控的合成数据
借助生成式 AI 的 API 和 SDK, NVIDIA Omniverse 可加速物理 AI 仿真。开发者使用基于 OpenUSD 构建的 NVIDIA Omniverse 创建 3D 场景,以准确模拟现实世界环境,从而训练和测试机器人和智能汽车。这些仿真可作为 Cosmos Transfer 的真值视频输入,并与标注和文本指令相结合。Cosmos Transfer 可在改变环境、照明和视觉条件的同时增强逼真度,从而生成可扩展的多样化世界状态。
此工作流可加速高质量训练数据集的创建,确保 AI 智能体从仿真有效推广到实际部署。
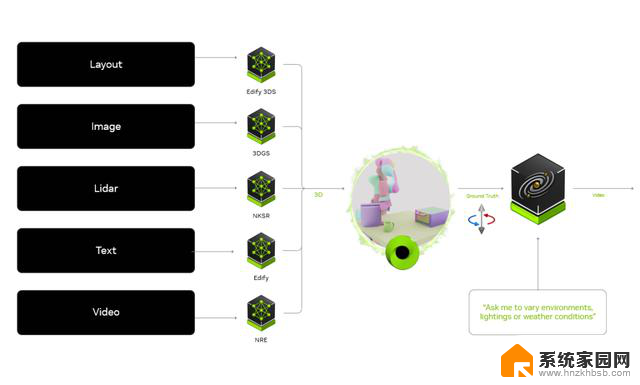
图 2. NVIDIA Omniverse 中的生成式 API 和 SDK 为 Cosmos Transfer 的真值模拟提供支持

图 3. 由 Cosmos Transfer 制作的逼真视频
Cosmos Transfer 通过在用于合成操作运动生成的 Isaac GR00T Blueprint 和用于智能汽车仿真的 Omniverse Blueprint 中实现逼真的照明、色彩和纹理来增强机器人开发,从而为训练提供不同的环境和天气条件。这种逼真的数据对于后训练的策略模型至关重要,可确保将仿真平稳地迁移到现实,并支持感知 AI 和 GR00T N1 等专用机器人模型的模型训练。
使用 Cosmos Transfer 运行推理
以下是使用 Cosmos-Transfer1-7B 模型进行推理的一些示例命令。
Cosmos Transfer 已根据 NVIDIA Open Model License 在 Hugging Face 上公开可用。生成 Hugging Face 访问令牌,使用 CLI 登录,接受 LlamaGuard-7b 条款,并按照 Cosmos-Transfer1 GitHub 说明操作。
以下命令可下载 Cosmos-Transfer1 的基础模型、tokenizer 和 guardrail 模型:
Cosmos WFM 可以后训练为 VLA 策略模型,其中视频输出被机器人执行的动作输出所取代。对于上下文,策略模型根据当前观察结果和给定任务生成物理 AI 系统要执行的操作。经过良好训练的 WFM 可以对世界的这种动态模式进行建模,并作为策略模型的良好初始化。
在 GitHub 上详细了解 Cosmos Transfer 示例。
Cosmos Predict 生成未来世界状态
Cosmos Predict WFM 旨在将未来世界状态建模为来自多模态输入(包括文本、视频和开始端帧序列)的视频。它使用基于 Transformer 的架构构建,可增强时间一致性和帧插值。
主要功能:
Cosmos Predict WFM 为训练机器人和智能汽车的下游世界模型奠定了坚实的基础。您可以对这些模型进行后期训练 ,以生成用于策略建模的动作而不是视频,也可以对其进行调整以实现视觉语言理解,从而创建自定义感知 AI 模型。
Cosmos 以智能方式进行
感知、推理和响应的推理
Cosmos Reason 是一个完全可定制的多模态 AI 推理模型,专为理解运动、物体交互和时空关系而构建。该模型使用 chain-of-thought (CoT) 推理来解释视觉输入,根据给定的提示预测结果,并奖励最佳决策。与基于文本的 LLM 不同,它为现实世界的物理推理奠定了基础,以自然语言生成清晰的上下文感知响应。
输入:视频观察和基于文本的查询或指令。
输出:通过长视距 CoT 推理生成的文本响应。
主要功能:
训练管线
Cosmos Reason 分为三个阶段进行训练,增强其在现实世界场景中推理、预测和响应决策的能力。
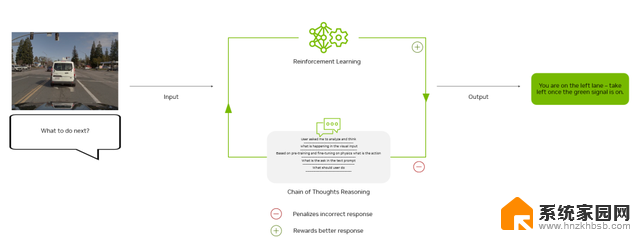
图 4. 强化学习反馈回路通过正反馈和模型调整不断改进
强化学习 (RL) :该模型会评估不同的推理路径,并仅在通过试验和奖励反馈做出更好的决策时自我更新。它不依赖人工标记的数据,而是使用基于规则的奖励:
开始使用
Cosmos WFM 在 Hugging Face 上提供,并在 GitHub 上为 Cosmos-Predict1 和 Cosmos-Transfer1 提供了推理脚本。
使用工作流指南,借助 Cosmos Transfer 生成合成数据:
https://docs.omniverse.nvidia.com/guide-sdg/latest/index.html