向着真实前进,显卡光追性能天梯图V1.0极速空间出品

2018年8月,英伟达发布了“图灵”架构,首次在 GPU 中引入了专门的光线追踪核心(RT Core),让实时光线追踪成为可能。
英伟达给具备RT core的显卡一个专属的尊贵标识:“RTX”,而之前的GTX被打入冷宫。

在图灵显卡刚发布时,官方公布的光追的游戏并不多,只有十一款,实际测试的情况让人失望,光追开启后,不仅帧数大幅度下降,而且效果也并没有什么惊艳表现,让人觉得这是一个“得不偿失”的技术,一度怀疑这是老黄心血来潮脑门一拍的产物。

黑神话悟空光追开启
然而,到了2023年12月,英伟达宣布支持光追的游戏已经高达500款,隔壁两家也看到了这个趋势,AMD从RDNA2开始,加入光线加速器(Ray Accelerators),争取追上英伟达的步伐。英特尔则在Xe HPG架构里增加了光追单元(Ray Tracing Unit,RTU),开启了自身的光追时代。

光追开启效果
不同的游戏,光追开启后对效果的增益不一样。获益较大的游戏有:
《赛博朋克 2077》、《黑神话:悟空》、《GTA6》、《刺客信条:影》、《看门狗》、 《战地5》、《我的世界》、《逆水寒Online》、《地铁离去》、《控制》、《德军总部:新血脉》、《荒野大镖客2》、《永劫无间》......等等。

光追关闭和开启效果对比
为了衡量显卡的光追性能,UL Solutions(纽交所上市公司)在3DMARK里增加了Port Royal测试子项,这是全球第一个面向实时光线追踪的性能测试工具。
在实际排序中,站长选取了Speed Way分数作为标尺,弃用Port Royal,主要有两点原因:
1、Port Royal 发布于 2019 年,基于早期的 DirectX Raytracing(DXR)开发,测试场景单一。Speed Way发布于2022年10月,完整支持 DX12U 四大特性(网格着色器、可变速率着色、采样器反馈和DXR 1.1)。
2、Port Royal 评分权重过度偏重光追单元算力。在现在的实际光追游戏里,采用的是光栅和光追踪相结合的“混合渲染”。普通场景用光栅化处理,光线追踪用于水面反射,玻璃折射、霓虹灯光等更具视觉效果的地方,以起到锦上添花的作用。Speed Way的评分体现了显存、着色器、光追单元综合调度,更贴近实际游戏的混合渲染负载。

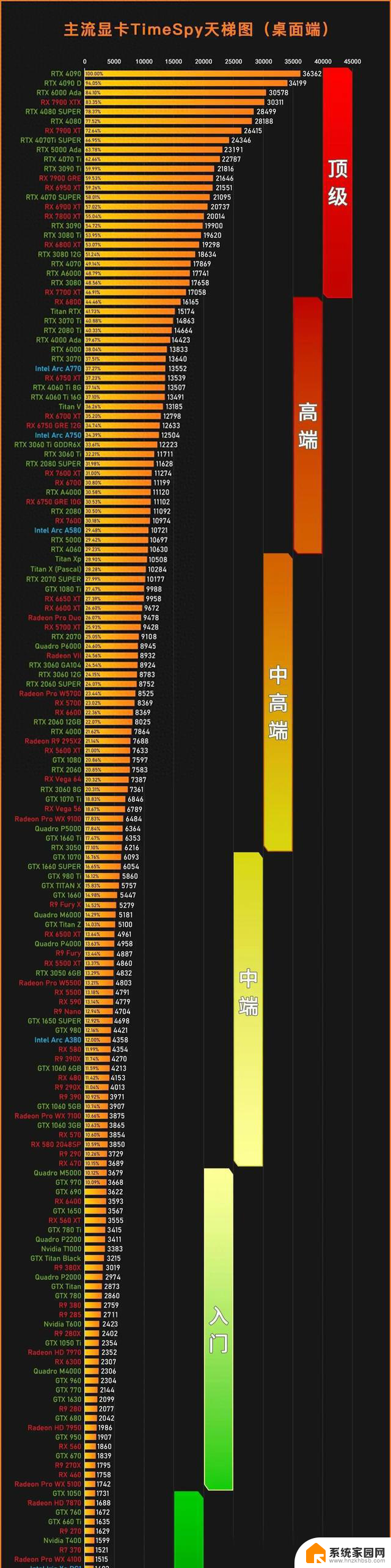
极速空间显卡光追性能天梯图V1.0
当前的显卡天梯图,通常是根据传统渲染分数排序,并不能体现其光追能力。因此,站长制作了显卡光追性能天梯图V1.0版。
解读(以RTX5070Ti和RX 9070XT为例)在传统渲染性能上,RTX5070Ti要比RX9070XT低大约10%。但光追性能反超对方20%,原因如下:
第一、光追核心第四代胜过第三代
英伟达在光追上有先发优势,RTX50系列已经升级到第四代 RT Core。AMD是从RDNA2开始加入光追世界的,RX9070XT隶属于RDNA4,采用自家第三代的光追核心。简单理解就是两位武林高手修炼内功,姓英的先练,当下到了第四层,姓A的后练,现在到了第三层。

第二、第五代 Tensor Core胜过第二代AI加速器
姓英的 Tensor Core和姓A的AI加速器表面看相似,都针对矩阵乘法和混合精度计算,用于加速深度学习任务。但二者在设计和性能上有显著异。
Tensor Core是独立专用单元,与 CUDA 核心物理分离,与 CUDA 核心并行工作,不占用图形渲染资源。AI加速器本质是流处理器(SP)的指令集扩展,并不是独立硬件,没有专属的晶体管区域,当执行AI加速器执行任务时,会占用CU内的矢量寄存器、缓存带宽等资源。正因为不是独立硬件单元,AMD 官方称其为 “AI Accelerators”(加速器)而非 “AI Cores”(核心)。
此时,可能部分读者会有这种疑惑,我们谈论的是光追,光追就谈RT cores,这和Tensor Core有何关系呢?
Tensor Core 是英伟达光追技术的基石,即不使用DLSS的超分和插帧,Tensor Core也全程参与光追的“AI优化”计算。

RT core和Tensor Core分工合作
光线追踪需要模拟大量光线路径,实时渲染无法计算所有光线(否则帧率会暴跌),RT core犹如计算专家,专注于几何与物理计算,而Tensor Core就相当于这位专家的智能助手,来解决“计算更高效,结果更逼真”的问题。
英伟达的第一代Tensor Core出现在Volta架构中(代表型号 Titan V、Tesla V100),之后是图灵架构(即RTX20系列)、到目前的RTX50系列显卡已经更迭到第五代。
AMD的AI加速器第一代出现在RDNA3上,到了RDNA4更迭到第二代。

光追开启
第三:显存原生带宽胜过等效带宽
RTX5070Ti是256bit/GDDR7显存,原生带宽896GB/s。
RX 9070XT是256bit/GDDR6显存,原生带宽640GB/S,另有64MB Infinity Cache,等效带宽可达一倍以上提升。
传统光栅化渲染按像素/三角形顺序处理,相邻像素共享大量数据。这时可以充分发挥Infinity Cache的威力,缓存命中率可达60–80%甚至更高,但在光追场景中,光线可能从场景A点瞬间跳至B点(如镜面反射),访问的数据(纹理、几何)无连续性,数据随机性强,缓存命中率大幅度下降,此时GDDR7原生带宽的优势就凸显出来。
以上是RTX5070Ti光追领先的三个主要原因,其它还有一些因素,例如能效比、显存管理,以及对开发者的生态支持等等。

光追开启
总结
在这个领域,两个人比赛马拉松,英伟达先跑两公里,AMD的是追赶者,他能追上吗?
在2017年2月以前,AMD大幅度落后于英特尔,之后发布了锐龙一代,直到2024年的ZEN5,只用了七年就打败了英特尔酷睿14代(IPC和能效比均领先对手)。
现在,从RDNA第一代开始算(2019年发布),AMD用十年时间,到2029年能赶超英伟达吗?
站长认为,很难,原因下文探讨。
注:如需显卡光追性能天梯图高清版,可到极速空间官网下载。