Arrow Lake架构解析:酷睿Ultra处理器,能耗比主打超能课堂(337)
 Arrow Lake架构概述
Arrow Lake架构概述Arrow Lake与Lunar Lake有着相同的新一代CPU内核,包括Lion Cove P-Core和Skymont E-Core,所以它们被划为同一代产品,两者也是由多个模块组成并采用Foveros先进封装技术组合在一起,但除此之外两者其实就没啥相似的地方了。
Lunar Lake是由计算模块和平台控制模块所组成,计算模块包含CPU、NPU和GPU,内存控制器、媒体引擎、显示引擎、IPU也在里面,基本上就是一个传统单芯片CPU没了PCIe控制器,而平台控制模块则包含PCIe、USB、Thunderbolt 4、WiFi、千兆有线网络MAC,此外还有安全模块,它的功能和传统的PCH没啥差异。Lunar Lake还把两颗LPDDR5封装到CPU的PCB上让笔记本主板设计变得非常紧凑,同时还能提升内存频率并降低40%的功耗。
而Arrow Lake的结构则沿袭自Meteor Lake,可以说Arrow Lake才是Meteor Lake真正的继任者,CPU同样由计算模块、SoC模块、图形模块、IO模块这四大模块组成,也都用Foveros封装在基础模块上。此外Arrow Lake上也有一个填料模块,它的作用就把顶盖覆盖范围内没有运算模块的部分填满,因为模块和散热顶盖之间需要有充分接触,否则由于压力不同会对芯片造成损伤。
Arrow Lake的计算模块是肯定与Meteor Lake上的不一样的,核心规模比采用相同内核的Lunar Lake大得多,最高能到8P+16E。在Lunar Lake上,E-Core并不挂在环形总线上,与P-Core通信要走NOC总线,也不能使用P-Core的L3缓存,所以英特尔是直接把它们叫作LP E-Core的。而Arrow Lake的P-Core与E-Core都在一个环形总线内,可共享最多36MB L3缓存。
Arrow Lake的SoC模块大概就是Meteor Lake上的小改,里面的NPU依然是第三代的,不是Lunar Lake上的第四代NPU,与Meteor Lake的SoC模块相比新增了对PCIe 5.0的支持,至于LP E-Core,目前在今天发布的Arrow Lake-S桌面处理器上是没有的,其他的移动处理器不好说。显示模块使用的是与Meteor Lake相同的Xe-LPG架构,但规模减半,IO模块应该是不一样的,因为桌面平台需要提供完整的PCIe x16,而移动版只有PCIe x8。
关于Arrow Lake各模块的制程工艺,计算模块用的是台积电N3B,图形模块使用N5P工艺,SoC和IO模块则是N6工艺,除了计算模块制程与Meteor Lake不一样外其他都是一样的。
接下来我们先来回顾一下Lion Cove和Skymont两个内核。
性能核:Lion Cove现在Meteor Lake所用的Redwood Cove对于上代Golden Cove来说可以说是小修小改,但Arrow Lake与Lunar Lake上的Lion Cove改动还是蛮彻底的,首先它的缓存结构就有很大变化。在L1数据缓存与L2缓存之间加了一层缓存,原来的L1数据缓存现在变成了L0数据缓存,容量同样是48KB,加载延迟从5周期降低到4周期;新增的L1数据缓存是192KB,加载延迟9周期;Arrow Lake的L2缓存是3MB,比Lunar Lake的2.5MB更大,它们都比上代的2MB要大,但加载延迟从16周期降低到17周期。Lunar Lake上的四个P-Core共享12MB L3缓存,而Arrow Lake则是P-Core与E-Core共享36MB缓存。
用于管理缓存的子系统数据转换后备缓冲区(DTLB)深度从96页增加到128页,以提高其命中率。地址生成单元/存储单元(AUG/STA)从2组增加到3组,这一改动使加载/存储管道的数量达到平衡,各有三个,而上两代都是三个加载与两个存储管道。
前段进行了重新设计,分支预测块增加了8倍,获取区块从以前的64字节增加到128字节,解码器由6个增至8个,微指令队数量144条目增加到192条目,微指令缓存从4K扩大到5.25K,并让缓存读取带宽增加了50%。这些改进的目的是为了能够改进代码转换和执行的性能和功耗。
Lion Cove的乱序引擎划分成整数和矢量区域,都具有独立的确定和重命名功能,这样可以省下大量的硬件开销,并降低能耗提升性能。乱序引擎的分配/重命名从6个增加到8个,退出从8个增加到12个,深度指令窗口从512个增加到576个,执行端口从12个增加到18个。
整数执行引擎的ALU加法器从5个增加到6个,junp单元从2个增加到3个,shift单元从2个增加到3个,乘法器从单个64×64的单元变成了3个64位乘法器,这些改动能为复杂的操作提供更强大的算力。
矢量单元的SIMD ALU从3个增加到4个,拥有两个4周期延迟的256位FMA,同事还有两个256位除法器,和前一代相比,单精度和双精度计算的吞吐量都有大幅提高。
超线程在Arrow Lake和Lunar Lake上都被移除了,并不是英特尔把超线程关闭了,而是直接移除了。其实英特尔做了两个版本的Lion Cove,开启超线程能在相同芯片面积下增加30%的IPC,但代价是增加20%的功耗,这在数据中心这种追求线程密度的产品上是很好的,但在客户端处理器上情况就不一样了,经过三代混合架构处理器的实践,已经证明了E-Core是比超线程更高效的多线程加速手段。
超线程并不是免费的,它需要额外的芯片面积。一个没有超线程的Lion Cove和一个开启超线程的Lion Cove相比,能效比提升了5%,单位面积性能降低15%,但把性能、功率、芯片面积全算起来效费比提升了15%,再加上Lunar Lake是为低功耗设备而准备的,所以英特尔直接就删掉了这部分的电路,把节省出来的功耗和芯片面积来换取内核的更高时钟速度和IPC。
频率控制也变得更为精细,此前处理器核心的频率变化步进是100MHz,现在大幅缩小到16.67MHz,这自然提高了能效,某些情况下甚至能达到更高的频率。
能效核:Skymont当年英特尔在Alder Lake上引入的Gracemont架构E-Core,IPC是向Skylake看齐的,而Arrow Lake与Luner Lake上的Skymont,它的IPC则是向Raptor Cove看齐,而这Raptor Cove就是现在13/14代酷睿里面的P-Core。
Skymont与上代Crestmont相比,整数性能提升了38%,浮点性能提升了68%之多,只需要1/3功耗就能达到与Meteor Lake的SoC上两个LP E-Core同样的性能,同功率下单线程性能是原来的1.7倍,最大功率性能更是达到原来的两倍。
与Raptor Cove相比,Skymont的单线程整数与浮点性能都高出2%,达到了当时定下让Lunar Lake的E-Core性能匹配Raptor Lake的P-Core的设计目标。
再来看性能与功耗的对比曲线,Skymont能用更低的功耗实现与Raptor Cove同等的性能,在上图中框起来的那个区间内,在最佳情况下,Skymont只需要60%的功耗就可达到Raptor Cove的同等性能,在同功率下可实现20%的性能提升。当然了,Raptor Cove的功率上限比Skymont高得多,所以整体性能上限也比Skymont更高,毕竟两者的定位完全不一样。
Skymont的分支预测单元每周期预测范围从64字节翻倍到128字节,这加快了指令提取速度,现在最多可并行提取96个指令字节。解码方面,Skymont每周期解码指令从6条增加到9条,比Crestmont提高了50%,Uop队列从64提高到了96,这是x86历史上最宽最广的解码能力。
同时Skymont引入了Nanocode的新功能,它允许每一个解码集群可以独立处理多个微代码流,把类似的微代码段组合在一起,以实现更高的并行性。
乱序执行引擎的分配队列从6宽度增加到8宽度,退出队列从8宽度增加到16队列, 新增依赖中断机制,可有效降低延迟。重排序缓冲区从之前的256个条目扩展至416个条目,物理寄存器文件、保留站和加载/存储缓冲区也得到扩展,这些改动可提高并行性和降低延迟。
执行引擎的调度端口增加到26个,拥有8个整数ALU,3个Jump接口,每周期可执行3个加载操作,这些均比上一代增加了50%,提升了整体的并行处理能力。
矢量单元现在拥有4个128位浮点与SIMD矢量,这使得Gigaflops和TOPs算力直接翻倍,增加的执行单元有助于提升AI方面性能。FMUL、FADD、FMA经过重新设计降低了延迟,FP舍入现在支持硬件加速。
加载/存储管道数量从原来的都是两个变成了现在拥有3个加载管道和4个存储管道,L2缓存TLB的大小从3096增加到4192,Skymont依然是四个核心共享4MB L2缓存,但现在L2缓存带宽番了一倍,这让核心之间通信速度翻倍,并降低了内存延迟并提高了数据吞吐量。
Arrow Lake计算模块虽然在Lunar Lake上Lion Cove与Skymont的性能提升相当明显,但到了Arrow Lake-S上由于是桌面处理器,所以功耗上限要高得多,实际上英特尔此前给出过性能与功耗曲线,两个新内核的IPC优势在低功耗区间优势较大,但随着功耗上升增幅就会减少,所以现在Arrow Lake-S给出的IPC提升其实是要比Lunar Lake时要小的,但对比现在的13/14代酷睿处理器,提升还是很明显的。P-Core的IPC提升相对要少一些,Lion Cove比Raptor Cove只有9%的提升,但E-Core的提升非常大,Skymont对比Gracemount提升了32%之多。
Arrow Lake计算模块内的核心排列也有所变化,从最初的12代酷睿开始,处理器内的P-Core集中放一边,而E-Core则集中放另一边的,到了Arrow Lake上,每个E-Core集群都会被两个P-Core左右夹着,这样设计的好处就是可以把发热量大的P-Core分散布置,这样就可把热源分散,有利于散热。
缓存方面,Arrow Lake明显变得更大了,和Raptor Lake相比,L3缓存的总容量依然是36MB没变,每组E-Core集群的L2缓存也是4MB,但P-Core的L2缓存从2MB增大到3MB,所以总L2缓存容量从32MB增大到40MB,这使得Arrow Lake的L2缓存总容量比L3缓存还大。
Xe-LPG架构GPU与媒体引擎Arrow Lake的核显与Lunar Lake不一样,没有使用最新的Xe2架构,依然是Meteor Lake上的Xe-LPG,这是单纯的产品定位问题,Arrow Lake无论桌面和移动平台,大多数都是搭配独显使用的,所以不需要那么好的核显。
当然了对比现在Raptor Lake处理器上的Xe-LP核显,Xe-LPG也是有升级的,加入了光追单元,不过Arrow Lake-S的核显只有4组Xe核心,所以性能是有限的,但Xe-LPG支持DP4a指令,支持XeSS可提升游戏帧率。不过由于XMX引擎的缺失,所以XeSS的效率是肯定没A系列独显以及Lunar Lake上的核显那么高的。
多媒体引擎对比Raptor Lake也有升级,现在最高支持8K 60Hz 10bit的HDR视频解码以及8K 120Hz 10bit的HDR视频编码,支持包括VP9、AVC、HEVC、AV1以及其他的传统格式。
显示方面,最多可支持4屏输出,支持HDMI 2.1、DP 2.1以及完整的eDP 1.4的输出规范,分辨率最高支持一个8K60 HDR,或者4个4K60 HDR,或者是更高刷新率的1080p或者1440p 360Hz。
平台AI算力36 TOPSArrow Lake上的NPU依然是Meteor Lake上的NPU3,所以这里也不太多介绍了,由于Arrow Lake-S桌面平台,所以有更高的功耗冗余,NPU算力从11.5 TOPS提升到了13 TOPS。而Arrow Lake的核显只可提供8 TOPS的算力,CPU的算力反而是最高的,有15 TOPS,平台整体AI算力为36 TOPS。
大家应该都发现Arrow Lake的NPU算力远没达到微软Copilot+PC的40 TOPS要求了,实际上英特尔此前和各软件开发商沟通过,即使以Meteor Lake现在的NPU算力,目前在市场上还没有被充分利用到。但AI也是未来的新兴趋势,所以英特尔还是把NPU放到了台式机处理器上。也考虑到对于台式机用户来说大多数会搭配高性能独显使用,所以目前Arrow Lake搭配的NPU是综合各种因素考虑得出的结果。
酷睿Ultra 200S系列处理器说完了Arrow Lake-S的技术部分,接下来我们来看看酷睿Ultra 200S系列处理器,与以往一样,首发的只有K系列产品,包括酷睿Ultra 9 285K、酷睿Ultra 7 265K/KF、酷睿Ultra 5 245K/KF。
和14代酷睿一样,酷睿Ultra 9是8P+16E,酷睿Ultra 7是8P+12E,酷睿Ultra 5则是6P+8E,新的酷睿Ultra处理器依然包含Thermal Velocity Boost、Turbo Boost Max 3.0和Turbo Boost 2.0三层加速技术,当中酷睿Ultra 9是全部都支持的,而酷睿Ultra 7则不支持TVB,而酷睿Ultra 5则只支持Turbo Boost 2.0。
当然了对于用户来说,知道具体型号的不同核心的睿频频率就够了。最顶级的酷睿Ultra 9 285K处理器P-Core单/双核睿频频率是5.7GHz,全核睿频频率5.4GHz,E-Core的全核睿频频率4.6GHz。酷睿Ultra 7 265K的P-Core单/双核睿频频率是5.5GHz,全核睿频频率5.2GHz,E-Core的全核睿频频率4.6GHz。酷睿Ultra 5 245K的P-Core单/双核睿频频率是5.2GHz,全核睿频频率5.0GHz,E-Core的全核睿频频率4.6GHz。
核显方面,酷睿Ultra 9/7的核显频率是2.0GHz,而酷睿Ultra 5的频率是1.9GHz。
酷睿Ultra 200S处理器支持CUDIMM内存,与之前的UDIMM DDR5内存不同,CUDIMM集成了时钟驱动器,不仅提升了内存的极限频率,还增强了系统的整体稳定性,让内存模块能够在更高频率下保持稳定的运行状态。酷睿Ultra 200S处理器最高支持JEDEC标准的DDR5-6400内存,如果使用支持XMP的CUDIMM内存的话频率可轻松达到8000MHz+,支持ECC,最大可支持单根48GB的内存,最大内存容量192GB。
新一代处理器更换了LGA 1851平台,首发的只有Z890主板,扩展能力非常丰富,Arrow Lake-S处理器本身可提供20条PCIe 5.0和4条PCIe 4.0,和两个Thunderbolt 4接口,当中SoC模块可提供4条PCIe 5.0和4条PCIe 4.0,IO模块则可提供16条PCIe 5.0与两个Thunderbolt 4,这16条PCIe可拆分成x8+x8或x8+x4+x4,这比12到14代酷睿只能拆成x8+x8灵活多了,有效增加了PCIe 5.0 M.2接口的数量。
而Z890 PCH可提供24条PCIe 4.0,平台可用PCIe通道数量多大48条,当中有20条是PCIe 5.0。USB接口和SATA数量与Z790没区别,最多14个USB接口,当中最多可提供5个USB 20Gbps,10个USB 10Gbps,10个USB 5Gbps,SATA接口数量最多8个。
PCH整合的网络设备和上代一样依然是千兆有线以及WiFi 6E无线,通过扩展,平台可最多提供4个Thunderbolt 5口,2.5GbE有线和WiFi 7无线网络。
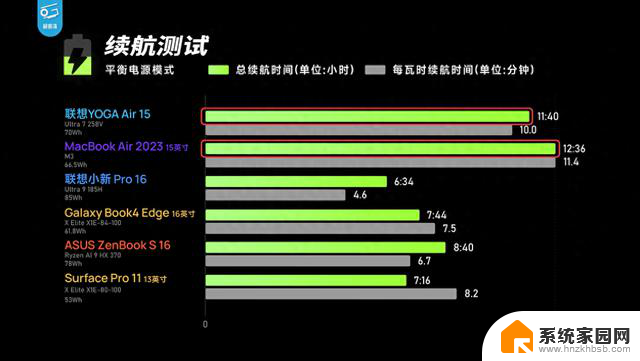
Arrow Lake处理器的设计目标是提升每瓦性能,要降低40%的整体平台功耗,并带来比上代15%的多线程性能提升,同时保持优秀卓越的游戏性能,并让处理器游戏时温度降低10℃。
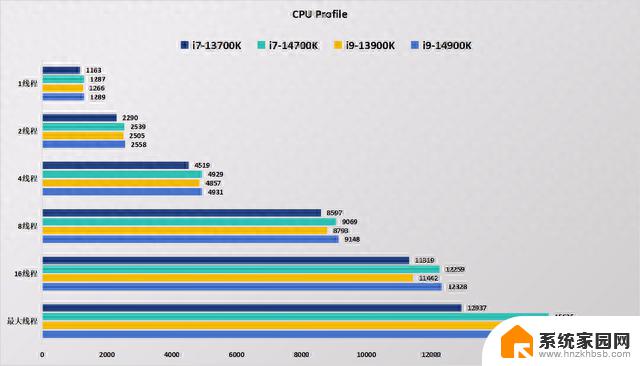
上图是酷睿Ultra 9 285K的官方性能测试,单线程性能整体较酷睿i9-14900K提升了8%,和锐龙9 9950X相比则平均高出4%。
酷睿Ultra 9 285K多线程性能整体较酷睿i9-14900K提升了15%,和锐龙9 9950X相比则平均高出13%。
如果看性能功耗曲线的话,酷睿Ultra 9 285K只需要125W的功耗就能发挥出酷睿i9-14900K在250W时的多线程性能,拥有相当强大的代与代每瓦性能提升。
酷睿Ultra 9 285K有着优秀的媒体引擎以及出色的软件支持,所以在视频编解码方面的测试可大幅领先对手,出色的多线程性能也在不少创作类软件中发挥出比对手更好的性能。
游戏性能方面,酷睿Ultra 9 285K并不能全面领先上代的酷睿i9-14900K,整体表现两者性能差异不大,但酷睿Ultra 9 285K能以更低的功耗发挥出同等的游戏性能。
这是官方的游戏功耗测试,酷睿Ultra 9 285K在不同游戏中的整体平台功耗要比酷睿i9-14900K低得多,最高可降低165W之多,平均降幅有73W其实也不低,不过需要注意的是这是平台整体功耗并不是CPU本身的功耗降幅,单论CPU功耗的话肯定不会降这么多的。
CPU功耗的降低自然会带来温度的下降,因此酷睿Ultra 9 285K的游戏时温度要比酷睿i9-14900K下降不少,至少也有10℃的下降,最多可降低17℃,平均降幅在13℃左右,对散热的需求明显降低。
不过与锐龙9 9950X对比游戏性能就不算很乐观了,只能说各有千秋,其实很多游戏帧率都是打平的。
至于Arrow Lake的AI性能,这里就不多说了,毕竟这是桌面处理器,和独显相比CPU的AI算力确实不算高,但NPU的引入确实可以降低部分AI应用的功耗,比如上图的人脸和动作识别类应用,NPU就能用较低的占用与功耗实现同样的功能,只不过目前适配NPU的AI应用确实不算多,这得等软件慢慢更新发展。
总结Arrow Lake虽然没超线程,但E-Core的IPC提升非常大,所以它依然可提供比Raptor Lake更出色的多线程性能,依然改进的重点是能耗比,仅需一半的功率就能发挥出Raptor Lake相同的性能。平台扩展能力比上代有了大幅提升,现在CPU可提供24条可用PCIe通道,当中有4条PCIe 5.0与4条PCIe 4.0是为SSD而准备的,PCIe 5.0 x16也可拆分成x8+x4+x4,也就是说平台在使用独显的同时可连接三个PCIe 5.0 M.2 SSD,这比上代只能扩展一个强多了。此外现在CPU可提供两个Thunderbolt 4口,这让Thunderbolt 4在台式机普及垫下基础,但我不确定板厂未来中低端Intel 800系主板会不会把这两个口做出来。
最后提一下未来的Arrow Lake-H与HX,它们都会在明年第一季度上市,大概率在CES 2025就能看到它们,Arrow Lake-HX就是Arrow Lake-S改封装,没啥好说的。Arrow Lake-H则最多6P+8E,NPU与Arrow Lake-S一样,核显变成了带XMX引擎的Xe-LPG架构,而且规模比Arrow Lake-S的大一倍,有8组Xe核心和8MB L2缓存,在XMX引擎的加持下核显的AI算力达到77 TOPS,比现在的8 TOPS高了不是一点半点,由于有着更高的功率,所以比Lunar Lake上的Xe2核显算力还高,但3D图像性能就不太好说了。