AMD反驳Nvidia在Instinct MI300X和H100 GPU性能对比中的说法,揭示真相
快速导读:AMD和Nvidia继续就Instinct MI300X和H100 GPU的性能展开争论。AMD提出了使用vLLM和FP16的有力观点,同时批评了Nvidia在TensorRT-LLM和FP8方面的选择性使用基准测试和封闭系统方法。
 AMD质疑Nvidia的基准测试选择和测试场景
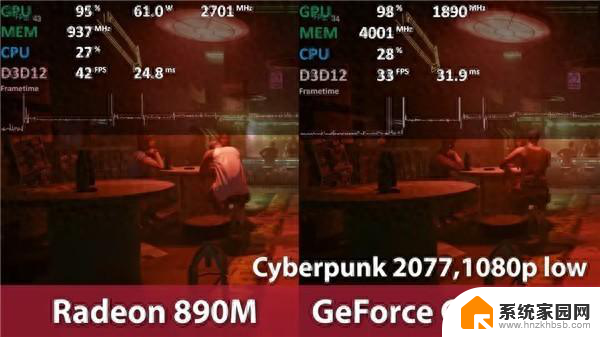
AMD质疑Nvidia的基准测试选择和测试场景AMD对Nvidia最近的说法作出回应,强调了Nvidia使用的基准测试中选择性的推理工作负载。AMD指出Nvidia在H100上使用了其内部的TensorRT-LLM,而不是广泛使用的vLLM。AMD还强调Nvidia将结果与使用TensorRT-LLM和FP8的DGX-H100进行了比较,而AMD则使用了vLLM和FP16数据集。AMD认为vLLM不支持FP8,并为使用vLLM的选择进行了辩护,因为它被广泛使用。
AMD批评Nvidia缺乏真实世界模拟AMD进一步批评Nvidia过于关注吞吐量性能,而没有考虑延迟和真实世界场景。AMD声称Nvidia的方法不能准确模拟真实世界情况。为了支持自己的观点,AMD使用Nvidia的TensorRT-LLM进行了三次性能测试。最后一次测试使用FP16数据集对比了MI300X和vLLM与H100和TensorRT-LLM之间的延迟结果。AMD还强调,其第二和第三个测试场景,显示了更高的性能和降低的延迟,使用了与Nvidia相同的选择测试场景。
AMD的优化对Nvidia的影响AMD展示了在MI300X和H100上同时运行vLLM时与H100相比的优化效果,性能提升了2.1倍。AMD向Nvidia提出评估自己的回应的挑战,但也敦促Nvidia承认行业对vLLM和FP16的依赖。并建议放弃它们转而使用TensorRT-LLM的封闭系统和FP8将是一个重大转变。AMD引用了一位Reddit用户的评论,将TensorRT-LLM称为“像劳斯莱斯附带的免费物品一样免费”。突显了Nvidia方法的潜在局限性。