微软重磅发布Phi-4推理模型,小型AI挑战大模型霸主-最新科技资讯
援引博文介绍,微软本次共推出 Phi-4-reasoning、Phi-4-reasoning-plus 和 Phi-4-mini-reasoning 三款模型,官方称该系列模型不仅延续了小型模型的高效特性,还在推理能力上实现重大突破。

该系列模型通过推理时间扩展(inference-time scaling)技术,擅长处理需要多步骤分解和内部反思的复杂任务,尤其在数学推理和代理型应用中表现突出,具备媲美大型前沿模型的潜力。
Phi-4-reasoning 是一款拥有 140 亿参数的开源推理模型,通过监督微调(Supervised Fine-Tuning,SFT)Phi-4,结合 OpenAI o3-mini 的高质量推理演示数据,并充分利用额外计算资源,生成详细的推理链条。

Phi-4-reasoning-plus 增强版通过强化学习(Reinforcement Learning,RL)进一步提升性能,tokens 用量比标准版多 1.5 倍,支持更高精度。
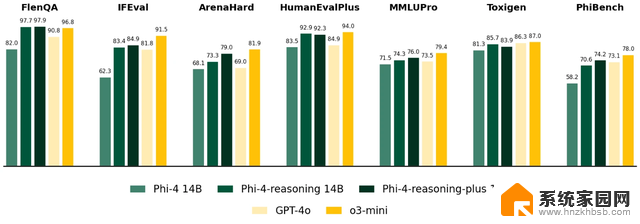
两款模型在数学推理和博士级科学问题测试中,均超越 OpenAI o1-mini 和 DeepSeek-R1-Distill-Llama-70B,甚至在 AIME 2025(美国数学奥林匹克资格赛)中击败 6710 亿参数的 DeepSeek-R1 满血模型。
Phi-4-mini-reasoning 专为计算资源有限的环境设计,是一款基于 Transformer 的紧凑型语言模型,优化用于数学推理。
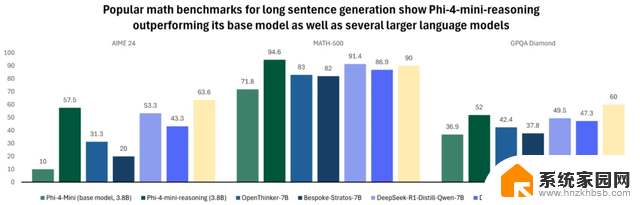
该模型通过 DeepSeek-R1 生成的合成数据微调,能在低延迟场景下提供高质量的逐步问题解决方案。这款模型覆盖从中学到博士级的百万级多样化数学问题,非常适合教育应用、嵌入式辅导和边缘设备部署。
在多项数学基准测试中,其 3.8 亿参数的表现超越 OpenThinker-7B 和 Llama-3.2-3B-instruct 等更大模型,甚至在部分测试中接近 OpenAI o1-mini 的水平。